缘由
最近在项目中遇到了语音关键词识别的需求,但是所要求的关键词大都为生僻字词。并且要求离线本地运行,不能使用云服务。不得已去了解研究了一下语音、关键词识别等技术。开始也是用如PyAudioAnalysis这样的开源库来进行音频分类,但效果并不理想。最终使用的方法为提取梅尔频谱图(Mel Spectrogram) + Resnet18进行多分类的方法。中文社区这方面的文章好像并不多,所以在这里来记录一下我的探索过程。
PyAudioAnalysis方案
在面对要求不高的音频分类任务(种类不太多,每个类别之间并不过分相似)时,直接使用PyAudioAnalysis这个库中提供的方法,便可以非常简单的训练好SVM或Random Forest这类模型,并可以取得较好的效果。
PyAudioAnalysis的具体细节这里就不过多介绍了,具体内容可以参考Github仓库页面,这里就展示一下最简单的训练SVM模型的过程。
安装
安装极为简单:
首先clone下载仓库到本地
git clone https://github.com/tyiannak/pyAudioAnalysis.git
进入文件夹后执行:
1
pip install -e .
便可以自动安装PyAudioAnalysis以及相关依赖库
训练传统模型
将音频数据集文件按照类型分文件夹放置,如下:
训练模型过程仅需调用一个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Import Dependencies
from pyAudioAnalysis import audioTrainTest as aT
# Set Dataset Path
DatasetPath = "Path of your dataset/"
# Get File Path List
for i in os.listdir(DatasetPath):
Folder_List.append(DatasetPath + str(i) + "/")
# Extract Features and Train The Model
aT.extract_features_and_train(
paths = Folder_List,
mid_window = 1.0,
mid_step = 1.0,
short_window = aT.shortTermWindow,
short_step = aT.shortTermStep,
classifier_type = "svm",
model_name = "VoiceModelSVM",
compute_beat = False,
)
其中,extract_features_and_train的paths参数需要输入一个包含每个Class的文件夹路径的List。这个函数会自动按照文件夹格式提取每个音频文件的特征向量,并训练一个分类器来进行分类任务。
每个音频文件会提取出一个长度136的特征向量
classifier_type参数为分类器类型,可供选择的有:svm , knn , randomforest , gradientboosting , extratrees。model_name参数为保存分类器模型的位置。
训练网络方案
建立数据集
由于任务需求的独特性,需要对项目指定的20个关键词进行数据集录制(具体内容见3.5附录)。编写数据集录制程序,并通过4虚拟TTS合成 + 10真人采集的方法共得到1948条关键词语音作为训练模型的数据集。随机提取出10%数据做为验证集。
如果PyAudioAnalysis训练出的模型分类效果并不能满足需求的话可以尝试以下方法。这里我以最终使用的梅尔频谱图(Mel Spectrogram) + Resnet18路径为例。
梅尔频谱图 Mel Spectrogram
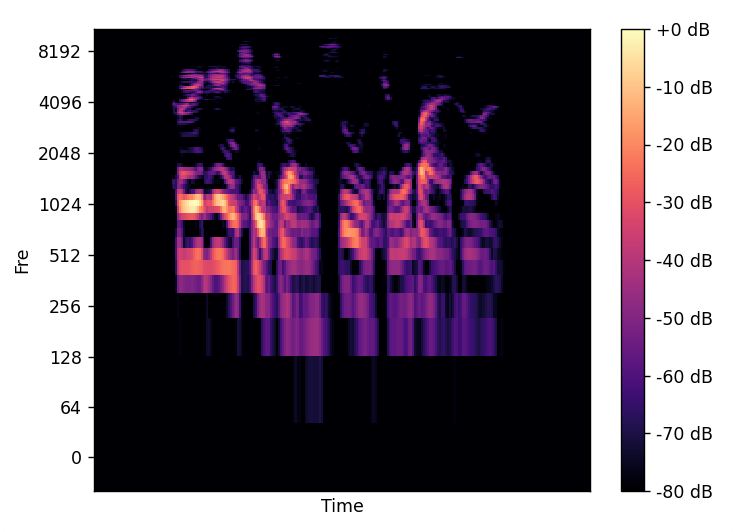
梅尔频谱在原始波形数据进行分帧、加窗、短时傅里叶变换(SFFT)后并通过一组Mel滤波器组操作后得到的特征。最终可以得到一个如下图的单通道图像数据:

使用Python的librosa库即可非常轻松的提取音频的Mel谱。使用的代码如下:
librosa.feature.melspectrogram()输出数据的Shape为(1, Mel_Dim, Time_Dim),其中Mel_Dim为函数中的n_mels参数大小,Time_Dim的大小和音频长度、n_fft、hop_length有关
提取Mel频谱图 对于每条语音数据,使用Python的Librosa库进行Mel频谱图提取,核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 载入数据
data, sr = librosa.load(Class + File, sr=None)
# 检查数据正确性
if(data.shape[0] < 1.3*sr):
print("Wrong Data",Class," : ",File)
continue
# 计算Mel频谱图
Spec = librosa.feature.melspectrogram(
y=data, # 输入音频
sr=sr, # 采样率
n_mels=128,
n_fft=2048, # FFT窗口的长度
hop_length=512, # 步长
)
# 匹配频谱图尺寸
Spec = cv2.resize(Spec,[256,128])
Spec = Spec.T
# 归一化数据
Spec = normalization(Spec)
对于每条音频,得到频谱数据形式为(128, 256),如下图:
训练Resnet-18模型
修改Resnet模型结构来适应本项目任务需求,如下:
1
2
3
4
5
6
7
8
9
def Resnet18():
# 载入Resnet18模型
Model = torchvision.models.resnet18(pretrained=False)
# 修改输出类别数
num_ftrs = Model.fc.in_features
Model.fc = nn.Sequential(nn.Linear(num_ftrs,20))
# 修改输入通道数
Model.conv1= nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3,bias=False)
return Model
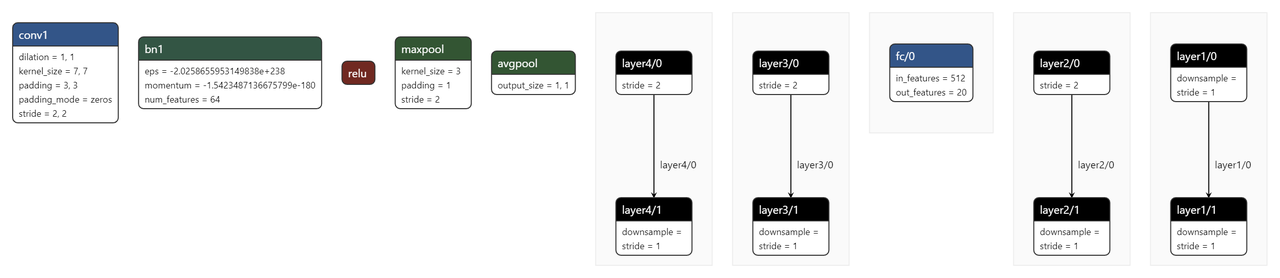
修改后的模型架构图如下:
在训练平台上,使用如下的超参数训练Resnet-18模型:
1
2
3
4
EPOCH = 400
Batch_Size = 64
Learning_Rate = 0.0003
Drop_Rate = 0.5
经过400个Epoch的训练后,模型收敛正常,Loss下降正常。训练精度达到预期,完成语音交 互技术的开发。
训练结果
在验证集上准确率Val_Accuracy:0.962162 ,误差Val_Loss: 0.207721。
绘制混淆矩阵图如下,该图表现了模型对20个类型中每个类型的分类情况:
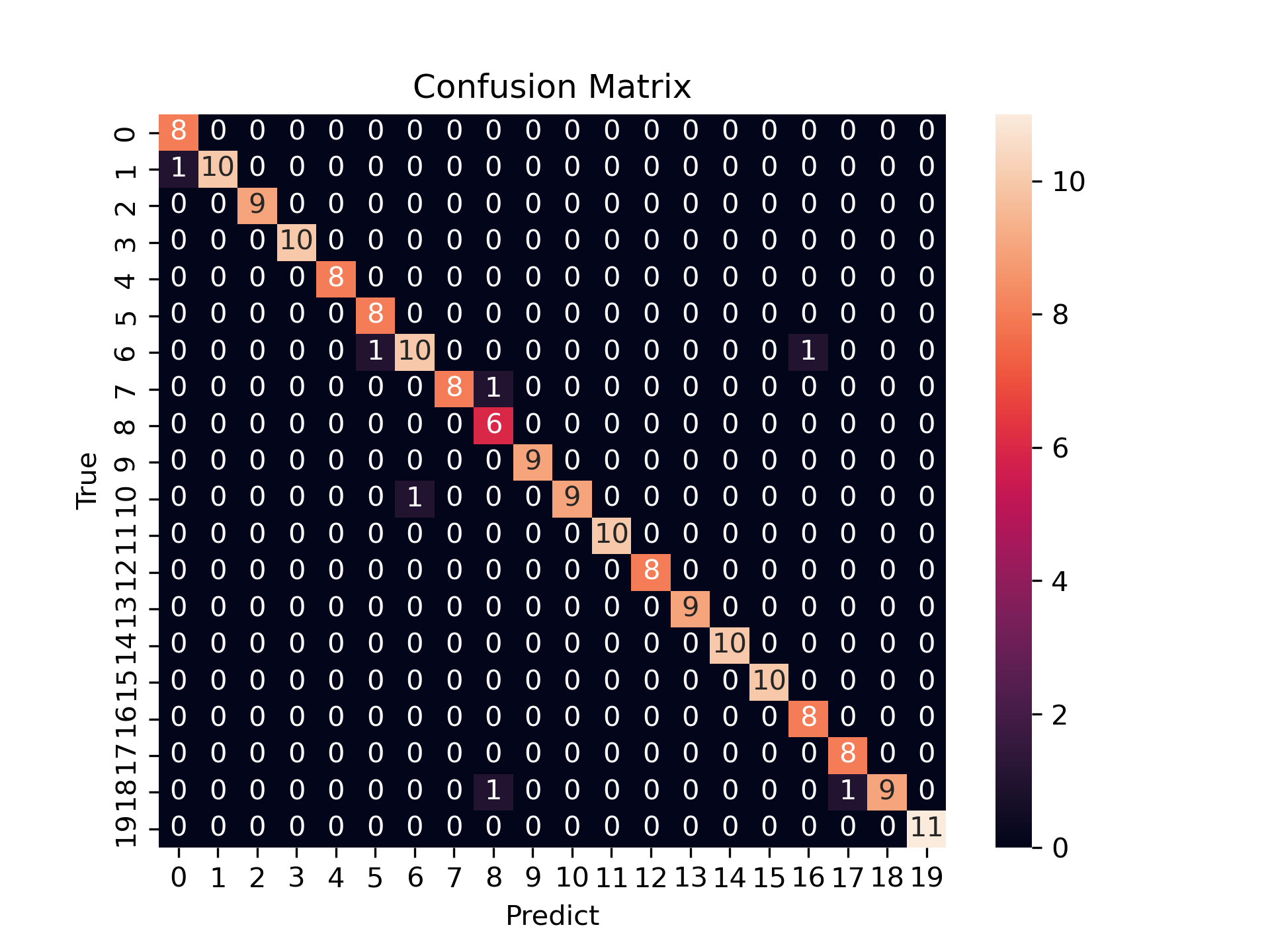
其中,横坐标为预测类别,纵坐标为真实类别。处于对角线上的元素代表分类正确。
可以看出,效果非常不错。